
AI集患ホームページ制作上級編-GEO・LLMOに備えよ
AI検索が当たり前になる時代を前に、自院のホームページをGEO・LLMOに対応させる取り組みが、個人クリニックの生き残りを大きく左右します。
初級編と中級編で築いた土台を活かし、既存記事をAIが引用したくなる構造へ書き換えていく作業が肝心になります。
逆転が起きてから動いても手遅れになる理由と、三段階で進めるロードマップの全体像を丁寧にお伝えします。

SEOからGEO・LLMOへ、集患競争のルールが変わる瞬間
集患競争のルールが、検索順位を争うSEOから、AIの回答に引用される位置を争うGEO・LLMOへと移り変わろうとしています。この変化の兆しを見逃さず、今のうちに備え始めたクリニックだけが、逆転後の世界でも選ばれ続けることになるでしょう。
検索順位から引用ポジションへ、ゲームのルールが根本から変わる
従来のSEOは、GoogleやYahoo!の検索結果で上位に表示されることがゴールでした。そのために内部構造を整え、外部リンクを集め、キーワード密度を調整する作業を積み重ねてきた方も多いはずです。
ところがAI検索の時代には、順位そのものがほとんど意味を持たなくなります。ユーザーはChatGPTやPerplexityに質問を投げかけ、AIが整理した一つの回答だけを受け取るからです。
その回答の中で、どのサイトが引用元として名指しされるか。ここが新しい集患の主戦場になります。順位ではなく引用、という発想の転換が出発点です。
GEO・LLMOとは何をする取り組みなのか
GEOとLLMOは、ChatGPTやPerplexityに代表されるAI検索に、自院の情報を引用させるための対応策を指します。呼び方は異なりますが、目指すゴールは同じです。
具体的には、AIが情報源として拾いやすい形に記事を書き換えたり、著者情報や出典を機械が読み取れる形式で整えたりしていく作業です。SEOの延長線上にありながら、評価する主体がロボットから言語モデルへと変わった点が決定的な違いになります。
SEOとGEO・LLMOの主な違い
- 評価の主体は、検索エンジンのロボットから大規模言語モデルへ移り変わる
- ゴールは検索順位の上昇から、AI回答文の中での引用獲得へと切り替わる
- 勝負のしどころはキーワード調整から、情報構造の明快さと出典の確かさに移る
- 読者層は検索結果を見比べる層から、AIの回答をそのまま信じる層へと広がる
逆転してから動いても間に合わない理由
現時点では、集患への貢献度は依然としてSEOの方が上回っています。AI検索を日常的に使う層はまだ一部に限られているためです。
とはいえ、この比率は確実に逆転する方向へ動いています。特に若い世代や情報感度の高い患者層では、検索よりもAIに質問する習慣がすでに根づきつつあります。
逆転が起きてから慌てて対応を始めても、その時にはすでに引用ポジションを押さえた先行クリニックが居座っているでしょう。後から参入する側に残される席はごくわずかです。
今から仕込むクリニックと後発組の決定的な差
今のうちにGEO・LLMO対応を進めておけば、逆転が起きた瞬間に自院が真っ先に引用される土台ができあがります。単なる順位の差ではなく、存在を認識されるかどうかの差になる点が怖いところです。
一方、対応が遅れたクリニックは、AIの回答の中で名前すら言及されない状態に置かれることになります。患者にとって「存在しないに等しい」という、集患上もっとも厳しい局面を迎えかねません。
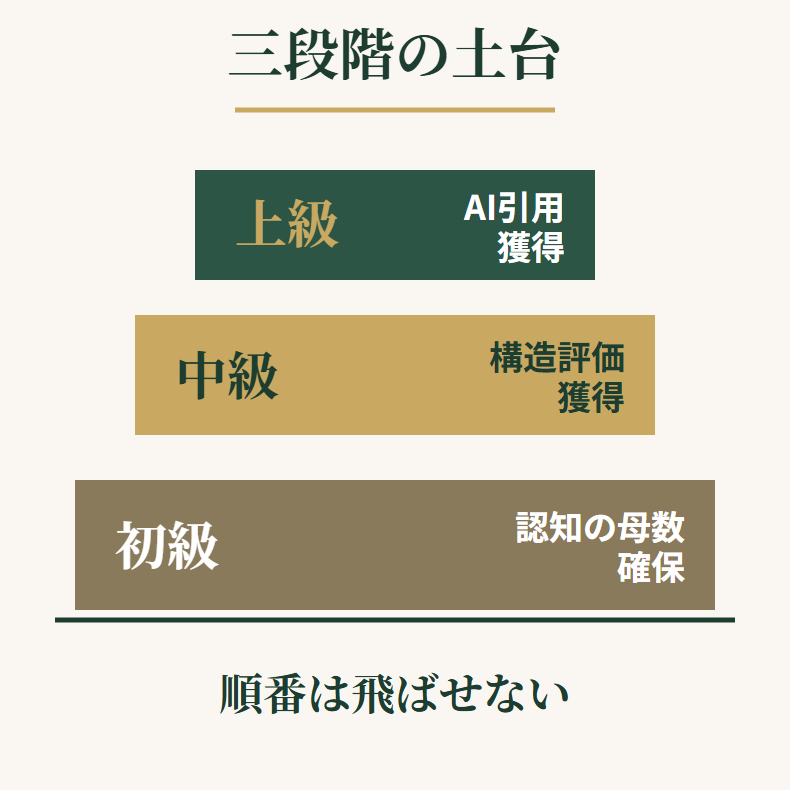
初級編・中級編を終えたクリニックだけが手にできる土台
上級編に進めるのは、初級編と中級編を愚直にやり切ったクリニックだけです。なぜなら、先に積み上げてきた成果物が、そのまま上級編の燃料へと変わっていくからです。ゼロからの参入組には追いつけない領域へと、ここで一気に差が開きます。
初級編で積み上げた認知の母数が燃料になる
初級編で取り組んできた記事の量産と検索流入の確保は、単なるアクセス稼ぎではありません。AIが学習する際の認知対象として、自院の名前が候補に含まれるための土台になります。
世の中に自院の存在を示す情報が十分にある状態を作っておくこと。この母数の厚みが、AI検索時代における引用可能性を根本から支えます。
中級編のトピッククラスターがそのまま転用できる
中級編で整備したトピッククラスター構造は、Googleに対して専門性を示す目的で組み立てられたものでした。その構造が、AIに対する専門性の提示にもそのまま活きてきます。
柱記事と子記事が論理的につながったクラスターは、AIが「この院はこの分野に詳しい」と判断する手がかりになります。中級編の成果物を作り直す必要はなく、上級編用に微調整するだけで済む点が大きな強みでしょう。
ゼロから参入する組が追いつけない構造
対照的に、これまで集患ホームページに本腰を入れてこなかったクリニックがGEO・LLMOだけ単独で進めようとしても、効果はほとんど出ません。AIが引用する相手として選ばれる前提条件である「認知の母数」と「構造的な専門性」が欠けているためです。
上級編の対応はあくまで仕上げの工程であり、下地なしに塗っても絵にならない。そんなイメージが近いでしょう。
土台なしに上級編へ進めば空振りに終わる
もし初級編と中級編を飛ばして上級編だけを急いでも、投下した労力に見合う成果は得られません。AIに引用される記事構造を整えても、そもそも引用対象として認知されていないからです。
遠回りに見えて、初級編から順番に積み上げた方がはるかに早く結果につながります。ここで焦って順序を崩さないことが、後の差を生みます。
初級編・中級編・上級編それぞれの成果物
| 段階 | 主な役割 | 主な成果物 |
|---|---|---|
| 初級編 | 認知の母数を確保する | 検索流入を生む記事群 |
| 中級編 | Googleの構造評価を得る | トピッククラスター |
| 上級編 | AI検索での引用を獲得する | GEO対応記事 |
AIに引用される記事構造とは何かを突き詰める
AIに引用されやすい記事には、明確な共通点があります。それは「問いに対して簡潔かつ正確に答える構造」を持っていることです。逆にいえば、この構造さえ満たせば、既存記事のリライトだけでも引用率を大きく伸ばせます。

問いに対して簡潔かつ正確に答える見出し設計
AIが記事の中身を読み取る際、まず見出しから要点を拾っていきます。見出しが抽象的な名詞止めになっていると、そこに何が書かれているかが機械には伝わりにくくなります。
患者が実際に抱く疑問をそのまま見出しに据える。「どの症状の時に受診すべきか」「治療期間はどのくらいか」といった、具体的な問いの形が引用されやすさを高めます。
結論を先に2〜3文で書くFAQ構造化
疑問文の見出しを置いたら、その直下には結論を2〜3文で端的に書くこと。この型はFAQ構造化と呼ばれ、AIがもっとも引用しやすい形式の一つです。
回答の根拠や補足説明は、結論の後ろに続けて書いていけば問題ありません。結論が最初に明示されていれば、AIは安心してそこを切り出し、回答の一部として提示します。
引用されやすい記事構造の特徴
| 構造要素 | 望ましい形 | 避けたい形 |
|---|---|---|
| 見出し | 患者の疑問文 | 抽象的な名詞止め |
| 冒頭 | 結論を2〜3文 | 背景説明から入る |
| 根拠 | 出典付きの数値 | 曖昧な形容表現 |
既存記事のリライトが新規量産より効く
上級編でやるべきは、新規記事を大量に作ることではありません。中級編までに仕上げたトピッククラスターの既存記事を、GEO対応フォーマットへ書き換えていく作業が中心になります。
すでに検索流入と構造評価を獲得している記事を、AI向けの形式に整え直す。この順序で進めるのが、労力対効果のもっとも高いやり方です。
引用されやすい記事に共通する三つの要素
引用率の高い記事を観察すると、疑問文の見出し、結論先出しの本文、出典付きの定量データ、という三点セットが揃っている場合が多くあります。どれか一つでも欠けると、引用確率は目に見えて下がるでしょう。
この三つを機械的にチェックしていくだけでも、既存記事の引用適性は大きく改善されます。感覚ではなく、型に従って点検する姿勢が大切になってきます。
E-E-A-Tを機械可読にする著者情報の整備
AIは「誰が書いたか」を重視する性質を持っています。そのため、著者情報が読み取れない記事は引用候補から外れてしまいます。E-E-A-T、つまり経験・専門性・権威性・信頼性を構造化データで機械可読にする作業が、上級編の中核をなします。

AIは「誰が書いたか」を重視している
同じ内容の記事が複数あった場合、AIは著者の属性を比較して引用元を選びます。医療分野であれば、医師が書いた記事か、資格のないライターが書いた記事かで、扱いに明確な差が生まれます。
人間の読者が無意識にやっている判断を、AIが構造化データを手がかりにしてやっているだけとも言えます。肩書きや経歴の情報が機械に伝わっていなければ、そもそも比較の土俵に載りません。
構造化データで専門性と経験を表現する
著者情報を機械に伝える手段として、schema.orgのPersonタグやMedicalWebPageタグを使った構造化データの実装があります。診療科、専門医資格、在籍学会、執筆実績などをコードで明示していくやり方です。
これらは見た目には現れないため、記事のデザインを変えずに実装できます。制作会社に依頼する際、構造化データの対応可否を必ず確認しておく姿勢が大切になるでしょう。
著者情報が読み取れない記事は引用候補から外れる
構造化データを入れていない記事は、AIから見ると「誰が書いたか分からない匿名コンテンツ」と同等に扱われます。医療情報という性格上、匿名記事は引用リスクが高いと判断されるため、候補から外されてしまうわけです。
内容がどれほど正確であっても、著者の機械可読性が欠けているだけで評価の舞台に上がれない。この点は上級編で最初に手を打ちたい領域になります。
E-E-A-Tを機械可読にする実装の要点
| 要素 | 内容の例 | 実装のポイント |
|---|---|---|
| 経験 | 臨床経験年数や症例数 | 著者プロフィールに明記 |
| 専門性 | 専門医資格 | hasCredentialで表現 |
| 権威性 | 所属学会や役職 | Organizationと紐付け |
| 信頼性 | 監修体制や出典 | reviewerを設定 |
出典付き定量データが引用率を決める
AIは曖昧な表現よりも、出典付きの定量データを優先的に引用します。「治療成績が良い」という書き方を「5年生存率◯%(出典:◯◯学会ガイドライン2025)」へと置き換えるだけで、引用される確率は大きく変わってきます。

曖昧な表現より具体的な数字がAIに選ばれる
「効果が高い」「患者満足度が高い」「多くの症例」といった形容の言葉は、人間には魅力的に響きますが、AIにとっては引用しにくい情報です。根拠が示されていないと判断されるため、回答生成の候補から落とされてしまいます。
代わりに、具体的な数値と出典がセットになった記述は、AIが迷わず拾い上げます。ここで必要なのは、表現の華やかさではなく、情報の硬さです。
学会ガイドラインや公的機関の出典を添える
医療分野では、学会のガイドラインや厚生労働省の統計など、公的な出典が数多く公開されています。これらを根拠として本文中で引用しながら数値を示すと、AIからの信頼スコアが一段引き上がるでしょう。
出典を書く際は、発行元、発行年、資料名の三点を揃えておくと機械的に読み取りやすくなります。リンクも合わせて設置できれば、なおよい形です。
曖昧な表現を数値と出典に置き換える実例
- 「治療成績が良い」を「5年生存率◯%(出典:◯◯学会ガイドライン2025)」に書き換える
- 「多くの症例」を「年間◯件の手術実績(自院集計・2025年)」に書き換える
- 「短期間で回復」を「平均入院期間◯日(自院過去3年平均)」に書き換える
表記の型を揃えれば機械可読性が跳ね上がる
数値の書き方にブレがあると、AIは同一情報として認識できません。「5年生存率」と「5年の生存率」が混在すると、別の指標として扱われる恐れがあります。
記事全体を通して、同じ概念には同じ表記を使う。単純な作業ですが、引用率に直結する地味な要点になります。
出典付きデータで差がつく書き方の実例
「患者の平均通院期間が短い」と書くだけでは印象に残りません。「平均通院回数◯回(自院過去5年集計)」と書けば、AIは回答の中で自院の名前と共に数字を提示してくれます。
このひと手間の積み重ねが、大手サイトとの差別化につながっていきます。労力はかかりますが、他では代替できない情報資産になります。
自院独自データこそが個人クリニック最大の武器になる
上級編における最大の武器は、自院の独自データです。症例数、治療実績、患者満足度といった数字は、他のどのサイトにも存在しません。AIにとって唯一の情報源である以上、引用せざるを得ない立場に立てる点が強みになります。
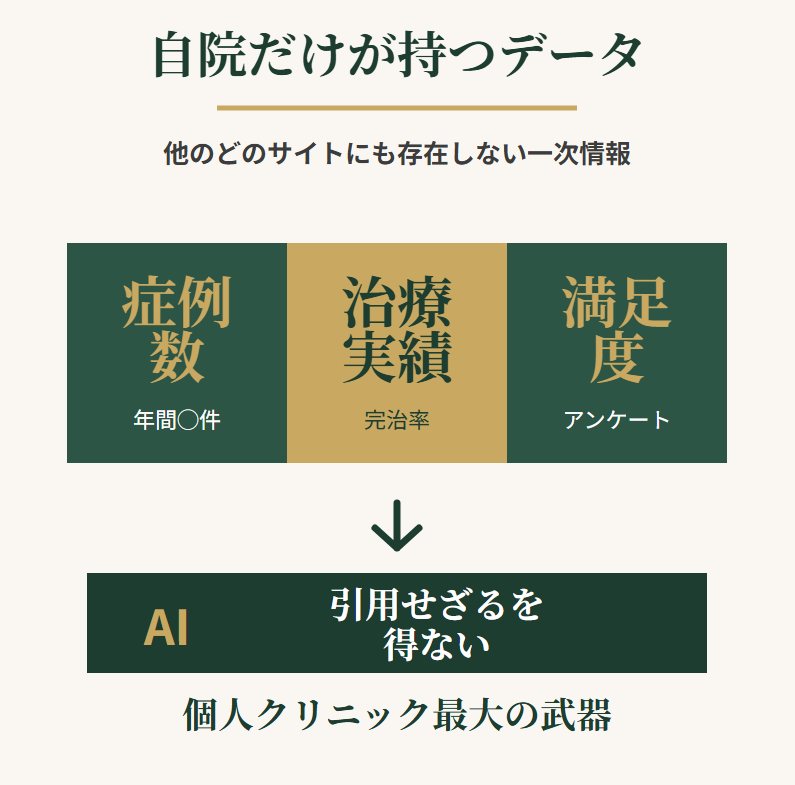
症例数や治療実績は他サイトにない一次情報
厚生労働省の統計にも、大手病院のサイトにも、医療ポータルにも、自院の数字は載っていません。つまり、自院だけが保有する一次情報の塊があるということです。
この一次情報を正しく公開していくことが、個人クリニックにとって他院との決定的な違いを作る素材になります。手元のカルテや集計表は、宝の山だと捉え直すべき時期に来ているでしょう。
大手病院サイトや医療ポータルに勝てる唯一の突破口
大手病院や医療ポータルは、資本力と人員で一般的な医療情報を大量に発信しています。この領域で個人クリニックが真っ向から戦っても、勝ち目はほぼありません。
しかし「自院の数字」という領域だけは、大手も入り込めない聖域です。そこに集中して情報を整え、AIへ機械可読な形で届けることが、個人クリニックが上級編で勝てる唯一の突破口になります。
AIにとって唯一の情報源は引用せざるを得ない
AIは同じ情報源が複数ある場合、権威性の高いサイトを優先します。ところが、自院の独自データについてはそもそも他に情報源が存在しないため、AIは自院サイトを引用するほかありません。
この構造は、個人クリニックが規模の不利を逆転できる数少ない場面です。独自データを整える労力は、そのまま引用ポジションの確保につながります。
自院が蓄積できる独自データの種類
| データ種別 | 例 | 公開時のポイント |
|---|---|---|
| 症例数 | 年間◯件の手術実績 | 集計期間を明記 |
| 治療実績 | 完治率や再発率 | 算出方法を開示 |
| 患者満足度 | アンケート結果 | 回答数と方法を併記 |
三段階ロードマップを逆戻りできない順序で進める
集患ホームページ制作は、初級編・中級編・上級編の三段階で構成されます。この順序は不可逆で、飛ばすことはできません。
初級編で認知の母数を確保し、中級編でGoogleの構造評価を得て、上級編でAI検索時代の引用ポジションを押さえる。この流れが骨格になります。
初級編で認知の母数を確保する
初級編では、検索流入を生む記事を継続的に増やしていきます。ここで積み上がる記事数と被リンク、ブランド言及の量が、後の工程すべての土台になります。
量を稼ぐ段階と軽視されがちですが、この母数がなければ中級編も上級編も機能しません。最初の半年から一年は、とにかく認知の器を広げていく時期と捉えておきましょう。
三段階ロードマップの全体像
| 段階 | ゴール | 主な作業 |
|---|---|---|
| 初級編 | 認知の母数を確保 | 記事量産と検索流入獲得 |
| 中級編 | 構造評価の獲得 | トピッククラスター構築 |
| 上級編 | 引用ポジション確保 | GEO対応リライト |
中級編でGoogleの構造評価を獲得する
中級編は、散らばった記事群を論理的な構造へと組み直す工程です。柱記事と子記事の関係性をつけ、内部リンクで専門性を示すトピッククラスターを築いていきます。
この段階で、Googleからの専門サイト評価が上がり、同時にAIが記事間のつながりを把握できる状態になります。上級編に直接つながる橋渡しの工程といえます。
上級編でAI検索時代の引用ポジションを押さえる
上級編では、中級編で整えたクラスター内の記事を、GEO対応フォーマットへ書き換えていきます。疑問文の見出し、結論先出し、出典付き定量データ、構造化データ、という四点を機械的に整えていく作業です。
新規記事の量産ではなく既存記事のリライトが中心になるため、初級編・中級編をやり切ったクリニックほど上級編の効率が上がります。
順番を飛ばせば上級編は機能しない
「上級編だけやれば楽に集患できるのでは」と考えたくなる気持ちは分かります。しかし、認知の母数も構造評価もない状態でGEO対応だけ進めても、AIからは見えない存在のままです。
三段階の順序は、集患という現場で長年検証されてきた不可逆の手順になります。近道はないと割り切って、一段ずつ積み上げていく姿勢が、最終的にはもっとも早い到達につながるでしょう。
よくある質問
GEO・LLMO対応はいつから始めるべきですか?
GEO・LLMO対応は、初級編と中級編をやり切った段階から始めるのが理想です。
母数や構造評価という土台がないまま上級編に踏み込んでも、成果は得にくいためです。
現時点で上級編に進める段階にあるクリニックほど、今すぐ準備に入る価値が高い時期になります。
GEO・LLMOへの対応は、既存記事のリライトだけで十分ですか?
基本的には、既存のトピッククラスター内の記事を書き換えていく作業が中心になります。
新規記事を量産するよりも、すでに検索流入と構造評価を獲得している記事を整え直す方が、労力対効果は高くなります。
ただし、抜けている論点があれば、その分だけ補強の新規記事を足す判断も必要です。
GEO・LLMO対応で必要な構造化データにはどのような種類がありますか?
schema.orgで定義されているPerson、MedicalWebPage、FAQPage、Articleなどが代表例になります。
著者情報や記事の性格、Q&A構造を機械可読にするために使います。
医療分野ではMedicalWebPage内のreviewerやlastReviewed属性を入れておくと、信頼性の評価につながりやすくなります。
GEO・LLMO対応にかかる期間の目安はどのくらいですか?
クラスター内の記事数にもよりますが、30本から50本規模で3か月から半年程度を見ておくと実際の進め方に合う目安になります。
見出しの書き換え、結論の先出し、出典の追加、構造化データの実装という四工程を順に回していきます。
一気に全記事へ手を入れるよりも、主力記事から段階的に進める方が運用負荷を抑えられるでしょう。
GEO・LLMOに取り組む際、医療広告ガイドラインとの関係で注意すべき点はありますか?
ガイドラインの範囲内で、誇大な表現や比較優良を避けることが大前提になります。
特に自院の独自データを公開する場合、集計期間や算出方法を明記し、根拠が確認できる形で示すことが大切です。
数字を出す際は、患者の誤解を招かない書き方を一文ずつ点検しながら進めていきましょう。
この記事を書いた人Wrote this article
AIで集患している人@山岡
自社の本業は医薬部外品等のネット通販。某巨大企業の社畜マーケターとしても活動中。個人マーケと大手マーケ、社長と社畜、の両岸を現在進行形で行っているのが最大の強み。某メジャー競技で全国優勝多数の元アスリート。生活も仕事もストイックすぎて誰ともなじめず友達はいないが悩んでもいない。AIエージェントをフル活用した「集患の全自動化」に挑戦中。すでに全自動化の仕組みは完成しており現在はテストを繰り返してバグを修正中。